はじめに
自社製品が日経225の構成銘柄企業にどれほど採用されているかを把握することは、企業のPR戦略において不可欠です。このデータは、自社の信頼性や市場での影響力を示す客観的な証拠となり、営業活動やマーケティング施策の強力な後押しとなります。

データ分析の経験がなくても、ChatGPTとGoogle Colabを使えば簡単に分析できます!
しかし、データ分析の専門知識がない方にとって、このような分析を行うのはハードルが高いと感じられるかもしれません。これまでは専門のデータアナリストに依頼したり、高額なツールを導入する必要がありました。
そこで注目したいのが、ChatGPTとGoogle Colabの活用です。ChatGPTの高度なコード生成能力と、Google Colabの手軽さを組み合わせることで、プログラミングの経験がなくても簡単にデータ分析が可能となります。
本記事では、これらのツールを用いて日経225銘柄リストと自社の顧客リストを照らし合わせ、重複分析を行う手順を詳しく解説します。具体的なコードも提供しますので、是非ご自身の業務に役立ててください。
作業手順
1. 日経平均株価ページからHTMLソースを取得
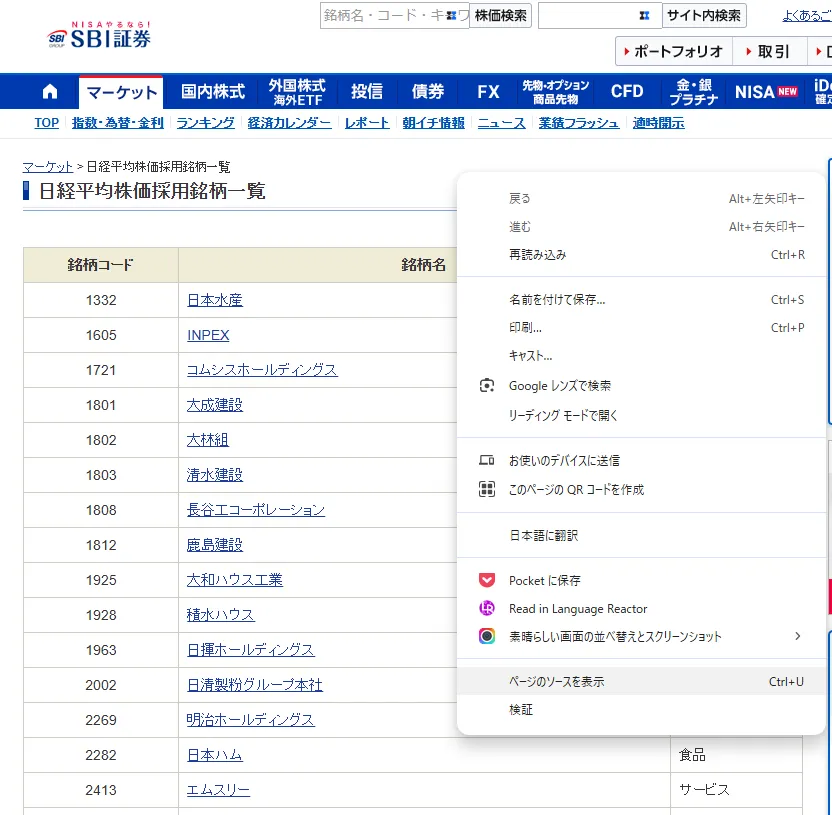
まず、SBI証券の日経平均株価ページにアクセスします。
ページ上で右クリックし、「ページのソースを表示」を選択します。
2. 銘柄リストのテーブルタグをコピー
表示されたソースコードから、構成銘柄が格納されている `table` タグを丸ごとコピーします。以下は当該コードの冒頭部分です。
コードの全体をコピーするのを忘れずに!省略せずに全銘柄分必要です。
<table class="md-l-table-01 md-l-utl-mt10">
<colgroup>
<col width="20%">
<col width="*">
</colgroup>
<thead>
<tr>
<th class="vaM alC">銘柄コード</th>
<th class="vaM alC">銘柄名</th>
<th class="vaM alC">業種</th>
</tr>
</thead>
<tbody>
<tr><td class="alC">1332</td><td><a href="/ETGate/...">日本水産</a></td><td>水産</td></tr>
<tr><td class="alC">1605</td><td><a href="/ETGate/...">INPEX</a></td><td>鉱業</td></tr>
<!-- 以下省略 -->
</tbody>
</table>注意: 上記は一部のみの抜粋です。実際には全ての銘柄を含む` table `タグ全体をコピーしてください。
3. ChatGPTにPythonコードの生成を依頼
ChatGPTに以下のプロンプトと、先ほどコピーしたHTMLタグ(全銘柄分)を入力します。
プロンプトは細かく指示を書くことで、より正確なコードを生成できます!
プロンプト:
### 指示
私は、HTMLから日本の企業リスト(銘柄コード、銘柄名、業種)を抽出し、顧客リストとの重複チェックを行いたいと考えています。顧客リストはCSVまたはExcelファイルとしてユーザーにアップロードしてもらいます。以下の機能を持つPythonコードを生成してください。
#### 要件:
1. **HTML入力の取得**:
- ユーザーからHTMLデータを直接入力してもらいます。そのHTMLには、企業情報(銘柄コード、銘柄名、業種)が含まれています。
- BeautifulSoupを使用してHTMLを解析し、企業情報を抽出してください。
- 以下の例としてHTML参照データを提供します。この形式に基づいてコードを生成してください。
```html
<-- SBI証券の日経平均株価ページのソースコードから取得したHTMLタグをここに貼り付けてください -->
```
2. **企業リストの作成**:
- 抽出した企業情報をPandasのDataFrameとして格納します(銘柄コード、銘柄名、業種)。
3. **顧客リストのアップロード**:
- 顧客リストは日本語のCSVまたはExcel形式でユーザーにアップロードしてもらいます。
- `ipywidgets`を使ってアップロードウィジェットを表示し、ファイルを読み込みます。
4. **企業名の正規化**:
- 企業名の正規化を行う関数を作成し、以下の処理を行います。
- 法人格(ホールディングス、HD、グループ、株式会社など)の削除。
- 特殊記号や空白の削除。
- 大文字・小文字の統一。
- 全角数字を半角数字に変換。
5. **重複チェック**:
- DataFrame内の企業名を正規化した上で、顧客リストとの重複チェックを行います。
- 重複しているかどうかの情報をDataFrameに追加し、重複率を計算して表示してください。
6. **データの表示と保存**:
- 重複チェックの結果を表示し、最終的にDataFrameをCSVとして日本語エンコーディングで保存する機能を追加してください。
- 作成したCSVファイルをユーザーがダウンロードする方法を示してください。
7. **使用するライブラリ**:
- `beautifulsoup4`、`lxml`、`pandas`、`ipywidgets`、`io`を使用してください。
#### その他:
- 必要なライブラリのインストール部分も含めてください。
- 生成されるコードは明確で、ユーザーが実行することで上記すべての要件を満たすようにしてください。
- Google Colab環境で動作することを前提とします。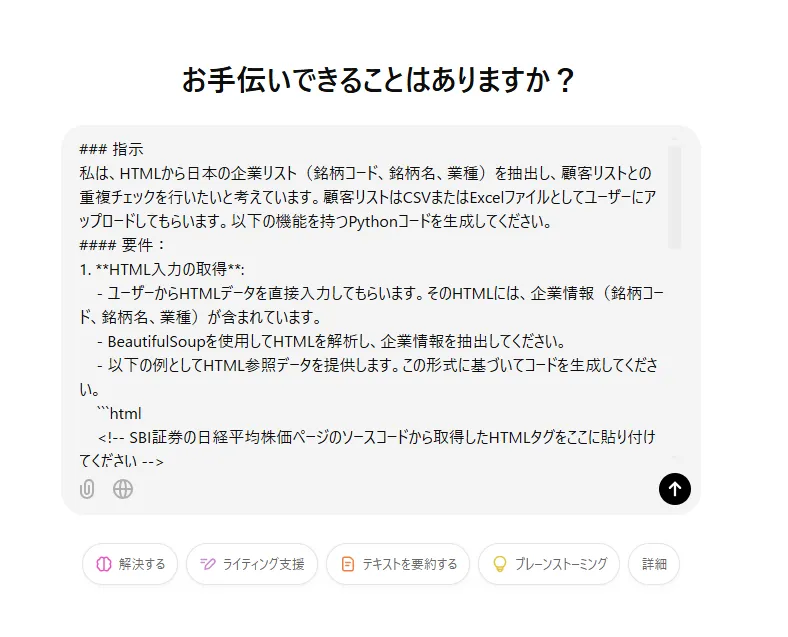
4. ChatGPTが生成したPythonコードをGoogle Colabに貼り付け
ChatGPTが生成したコードのサンプルは以下のようになります。このコードをGoogle Colabの新しいノートブックに貼り付けて実行します。
# 必要なライブラリをインストール
!pip install beautifulsoup4
!pip install lxml
!pip install ipywidgets
!jupyter nbextension enable --py widgetsnbextension
# 必要なライブラリをインポート
from bs4 import BeautifulSoup
import pandas as pd
import re
from IPython.display import display, FileLink
import ipywidgets as widgets
import io
# HTMLデータをユーザーに入力してもらう
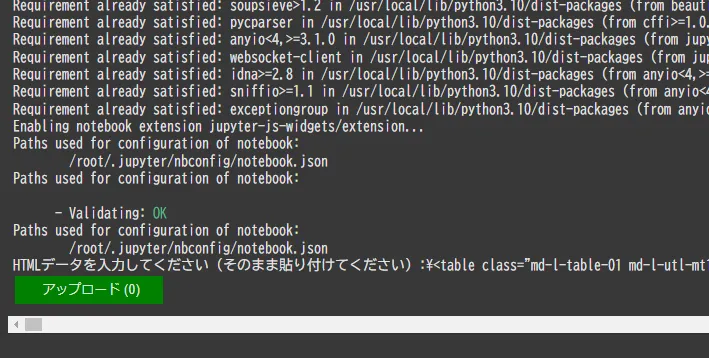
html_data = input("HTMLデータを入力してください(そのまま貼り付けてください):")
# BeautifulSoupでHTMLを解析
soup = BeautifulSoup(html_data, "lxml")
# テーブルを取得
table = soup.find("table")
# テーブルの行を取得
rows = table.find_all("tr")
# データを格納するリスト
codes = []
names = []
industries = []
# データの抽出
for row in rows[1:]: # ヘッダーを除く
cols = row.find_all("td")
if len(cols) == 3:
codes.append(cols[0].text.strip())
names.append(cols[1].text.strip())
industries.append(cols[2].text.strip())
# DataFrameの作成
df = pd.DataFrame({
"銘柄コード": codes,
"銘柄名": names,
"業種": industries
})
# 顧客リストのアップロードウィジェット
upload_widget = widgets.FileUpload(
accept='.csv, .xlsx',
multiple=False,
description='アップロード', # ボタンの文字を変更
style={'button_color': 'green'} # ボタンの色をグリーンに設定
)
display(upload_widget)
# アップロードされたファイルの読み込み
def on_upload_change(change):
if len(upload_widget.value) > 0:
uploaded_file = list(upload_widget.value.values())[0]
content = uploaded_file['content']
filename = uploaded_file['metadata']['name']
if filename.endswith('.csv'):
customer_df = pd.read_csv(io.StringIO(content.decode('utf-8')))
elif filename.endswith('.xlsx'):
customer_df = pd.read_excel(io.BytesIO(content))
else:
print("CSVまたはExcelファイルをアップロードしてください")
return
# 顧客リストの最初の列を使用
customer_list = customer_df.iloc[:, 0].tolist()
proceed_with_analysis(customer_list)
upload_widget.observe(on_upload_change, names='value')
# 企業名の正規化関数
def clean_company_name(name):
name = re.sub(r'(ホールディングス|HD|グループ|株式会社|カンパニー|インク|リミテッド|本社)', '', name)
name = re.sub(r'[\s\(\)・\-]', '', name)
name = name.lower()
name = name.translate(str.maketrans('0123456789', '0123456789'))
return name
# 重複チェックと結果表示
def proceed_with_analysis(customer_list):
df['正規化銘柄名'] = df['銘柄名'].apply(clean_company_name)
customer_list_cleaned = [clean_company_name(name) for name in customer_list]
df['顧客と重複'] = df['正規化銘柄名'].isin(customer_list_cleaned)
duplicate_count = df['顧客と重複'].sum()
total_companies = len(df)
duplicate_rate = (duplicate_count / total_companies) * 100
display(df)
print(f"重複率: {duplicate_rate:.2f}%")
# CSVを日本語エンコーディングで保存
df.to_csv("nikkei225_analysis.csv", index=False, encoding='cp932')
print("左側のメニューから 'nikkei225_analysis.csv' をダウンロードしてください。")
5. コードを実行
コードを実行すると、以下の手順で操作が進みます:
1. HTMLデータの入力
プロンプトが表示されるので、先ほどコピーしたHTMLデータ(`table`タグ全体)をそのまま貼り付け、Enterキーを押します。
2. 顧客リストのアップロード
アップロードウィジェットが表示されるので、CSVまたはExcel形式の顧客リストファイルを選択してアップロードします。
顧客リストは企業名が1列目にある形式で準備してください!
3. 重複チェックの結果表示
コードが実行され、日経225銘柄リストと顧客リストの重複チェック結果が表示されます。
4. 重複率の表示
重複率が計算され、画面上に表示されます:
重複率: xx.xx%5. CSVファイルのダウンロード
重複チェック結果を含むCSVファイルが表示され、左側のメニューから 'nikkei225_analysis.csv' をダウンロードできます。
おわりに
今回、ChatGPTとGoogle Colabを活用して、日経225銘柄リストと自社の顧客リストを照らし合わせる方法を解説しました。データ分析の経験がなくても、これらのツールを使えば効率的かつ簡単に分析を行うことができます。
この手法を用いることで、自社の市場浸透度やブランド力を客観的なデータで把握し、戦略的な意思決定に活かすことが可能となります。また、データ分析に対する抵抗感を減らし、業務の効率化にもつながります。
まずはこの方法を試してみて、データドリブンなビジネスの第一歩を踏み出してみてはいかがでしょうか。
日経225銘柄リストと顧客リストの重複分析手順 ビジュアルまとめ
\この記事をシェアする/
当ブログはリンクフリーです。SNSやブログでご紹介いただけると嬉しいです。
Instagramでフォローする
カフェ開業の日々や、コーヒーの魅力をInstagramでも発信中!
@ofuna_coffee をフォローデータ分析に関するよくある質問
Google Colabは有料ですか?
Google Colabには無料版と有料版があります。今回紹介した分析であれば、無料版で十分に実行可能です。大規模なデータ処理や長時間の実行が必要な場合は、有料版の利用を検討してください。
プログラミングの知識が全くない場合でも実行できますか?
はい、実行可能です。本記事で提供しているコードをコピー&ペーストし、指示に従って必要なデータを入力するだけで分析を実行できます。プログラミングの知識は不要です。
顧客リストのフォーマットに制限はありますか?
CSVまたはExcel形式のファイルで、企業名が1列目に記載されている必要があります。企業名の表記は完全に一致している必要はありません。コード内で法人格の削除などの正規化処理を行います。